Nonverbal Communication in Online Meetings: What Survives the Screen
Which nonverbal cues survive a video call and which don't, what the research says about gaze, latency and Zoom fatigue, and how facilitators can adapt.

You have run the session well, or so it feels. Then you switch to gallery view and scan twenty faces for a read on the room. Half the cameras are off. The ones that are on show heads cropped at the chin, a frozen frame, a person clearly looking at something else. You are trying to read body language through a periscope, and the medium is fighting you the whole way.
Nonverbal communication does not disappear on a video call. It gets filtered. A handful of cues come through, several arrive distorted, and a few vanish entirely, and most of us never learn which is which. This guide sorts them out, grounds each claim in the research, and gives facilitators a practical way to work with what the screen actually transmits. If you want the wider map of how people default to different communication patterns, start with our communication styles at work guide; this piece is about the specific channel that breaks first when you go remote.
The short answer
On a video call you can still read facial expression, vocal tone, head movement, and rough gaze direction. You lose mutual eye contact, full-body posture, gestures below the frame, physical distance, and almost all of the group-level cues that tell you how a room is reacting together. The popular idea that body language carries 93% of meaning is a misreading of one 1967 study and should not guide how you run a meeting. The bigger problem is that staring at a grid of faces is genuinely exhausting, a phenomenon researchers have traced to nonverbal overload rather than to screen time alone.
For facilitators, the takeaway is not “read harder.” It is to stop relying on a degraded channel and start designing the interaction so people can signal clearly anyway: explicit turn-taking, verbal backchannel, a deliberate choice of speaker versus gallery view, and a healthy scepticism toward any tool that claims to read emotion off a webcam.
What “nonverbal communication” actually covers
Nonverbal communication is everything you exchange without words: facial expression, gaze and eye contact, gestures, posture, the distance you keep from people, touch, and the sound of your voice apart from its content. Communication scholars usually group these into channels, kinesics for body movement and gesture, oculesics for eye behaviour, proxemics for the use of space, and paralanguage for tone, pitch, pace, and pauses (Louisiana State University, Fundamentals of Communication, 2021). In a physical room you process all of them at once, mostly below conscious awareness.
That last point matters for what follows. Nonverbal cues normally arrive as a rich, redundant bundle. You read a colleague’s hesitation from their posture, their pause, their glance at the door, and the half-step back they take, all confirming each other. Strip the channel down to a head-and-shoulders rectangle and that redundancy collapses. You are left guessing from one or two signals where you used to triangulate from six.
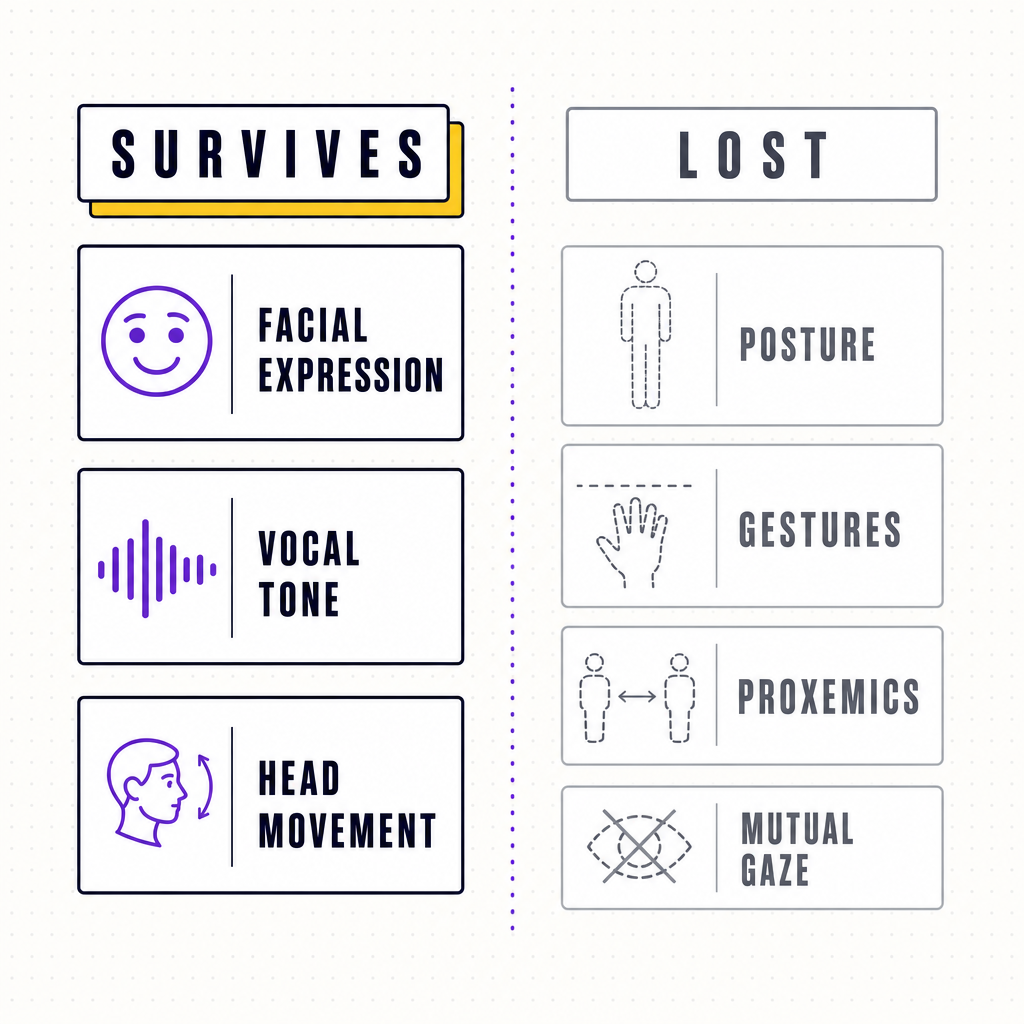
Which cues survive a video call, and which don’t
Some channels make it through the webcam intact, some get warped, and some are simply gone. Knowing the difference stops you from over-reading what is left.
What survives reasonably well is the upper face and voice. Expressions around the eyes and mouth, head nods and shakes, and paralanguage, your tone, pace, and pauses, all transmit, which is why an audio-rich call can still feel warm. What gets distorted is gaze. Because the camera sits above or beside the screen, looking at someone’s face means looking away from the lens, so genuine mutual eye contact is almost impossible on a standard setup. Research on collaborative learning found that systems engineered to restore real-time mutual gaze improved both collaboration quality and learning outcomes, which tells you how much the ordinary, gaze-broken setup is costing you (Bente and colleagues, International Journal of Computer-Supported Collaborative Learning, 2014).
What disappears altogether is most of the body. Posture, hand gestures that fall below the desk line, the fidget, the lean-in, and the use of physical space are all cropped out of frame. So are the group cues you rely on most as a facilitator: the side glance between two colleagues, the ripple of people shifting when an idea lands badly, the quiet side conversation. A video grid shows you a mosaic of isolated individuals, never the room as a single organism.
In person: you notice three people lean back and fold their arms when the timeline slips. On video: you notice nothing, because forearms and torsos are below the frame, and there is no shared physical space for the reaction to ripple through.
The Mehrabian myth, and why it misleads remote teams
If you have ever been told that communication is “7% words, 38% tone, 55% body language,” you have met the most misapplied statistic in the field. The numbers come from two narrow 1967 experiments by Albert Mehrabian on how people resolve conflicting signals about feelings and attitudes, judging single words against tone of voice and facial photographs (Mehrabian, summarised in the Albert Mehrabian research record, Wikipedia, 2024). They were never a general law of communication, and Mehrabian himself has spent decades warning against the way they get quoted.
The practical damage is real. If you believe body language carries 93% of meaning, you will conclude that a video call, which mangles exactly that channel, has stripped out almost all communication, and you will either panic or over-interpret every twitch on screen (Watermark Learning, “Correcting the Mehrabian Myth,” 2023). The honest reading is the opposite. Words and vocal tone, the channels that survive video best, carry far more of the load than the myth allows. Your meeting is not 93% broken just because you cannot see everyone’s hands.
Why a grid of faces is so tiring
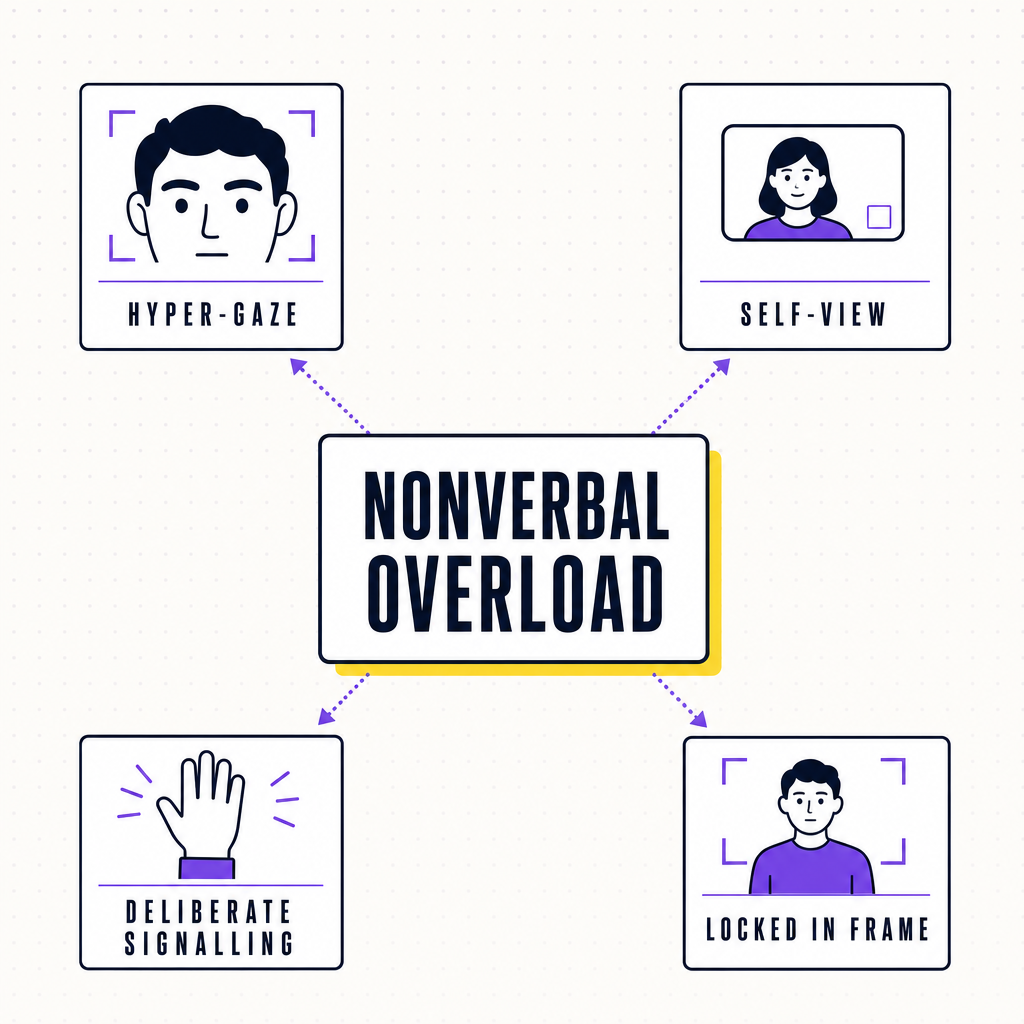
Video meetings exhaust people, and the reason is not simply “more screen time.” Jeremy Bailenson of Stanford’s Virtual Human Interaction Lab argued that the format imposes a specific kind of nonverbal overload (Bailenson, Technology, Mind, and Behavior, 2021). Four mechanisms do the work: an unnatural volume of close-up eye contact, the cognitive effort of sending and reading nonverbal cues deliberately rather than automatically, the constant sight of your own face, and the way sitting locked in frame removes the movement people normally use to think.
Each of these maps onto something a facilitator can change. The wall of faces in gallery view creates the hyper-gaze problem, since the brain reads a face filling your field of view as an intimate, high-stakes encounter, and a grid of them multiplies the effect (Stanford VHIL, “Nonverbal Overload,” 2021). The self-view acts as an all-day mirror, and research on Zoom fatigue repeatedly points to that self-monitoring as a major drain (PCMA, “Zoom Fatigue Causes,” 2021). The deliberate-signalling tax is why a two-hour workshop online leaves people more wrung out than the same workshop in a room.
The fix is not motivational. It is structural: hide self-view, drop to speaker view for focused stretches, and build in real breaks where cameras go off and bodies move.
Latency quietly breaks the conversation
Human turn-taking runs on a startlingly tight clock. Across languages, the gap between one speaker finishing and the next beginning averages around 200 milliseconds, faster than the time it takes to plan a word, which means we predict the end of a turn and launch our reply before it arrives (Stivers and colleagues, turn-taking timing research, 2009; PMC archive, 2014). It is a feat of split-second coordination we never notice, because in person it just works.
Network latency wrecks that timing. Add a few hundred milliseconds of delay and the micro-signals that hand the floor from one person to the next stop lining up. The result is the familiar online stutter: two people start at once, both stop, both apologise, or a question lands into total silence because nobody can read whose turn it is. The conversation has not broken because people are rude or disengaged. The nonverbal traffic-control system that governs turn-taking has lost its timing, and no amount of goodwill restores it. This is why throwing an open question to a grid of twenty rarely works.
Cameras on or off? The evidence is mixed
The instinct to mandate cameras-on for “engagement” runs into a genuinely split literature, and honesty here beats a clean rule. A within-person field experiment found that camera use during virtual meetings increased fatigue, and that the effect was stronger for women and for newer employees, the people most prone to self-presentation pressure (Shockley and colleagues, Journal of Applied Physiology-adjacent organisational research, 2021). On that reading, forcing cameras on taxes exactly the people already carrying the heaviest load.
Other work pushes back. A separate study of camera use in online classes reported that having cameras on supported student engagement without a measurable rise in fatigue (camera-usage classroom research, 2022). The two findings are not as contradictory as they look: context, group size, and whether the camera is voluntary all move the result. The defensible position for a facilitator is to make cameras a default-on invitation rather than a surveillance rule, to normalise camera-off stretches for long sessions, and to never treat a black tile as proof of disengagement.
The trap of AI “emotion detection”
A growing class of meeting tools promises to read engagement or emotion from participants’ faces in real time. Treat these claims with deep suspicion, on both scientific and legal grounds. Scientifically, most are built on the outdated assumption that a fixed set of facial expressions maps cleanly onto universal inner emotions, a view that modern affective science, led by Lisa Feldman Barrett’s work on the constructed nature of emotion, has largely rejected. A camera can estimate which muscles moved. It cannot read a feeling, and expressions are far more context-dependent and culturally variable than the marketing implies.
Legally, the ground has already shifted. As of February 2025, the EU AI Act prohibits emotion-recognition systems in workplaces and educational settings under its banned-practices article, with penalties at the top tier of the regime (EU AI Act analysis, vendor and industry coverage, 2025). For any L&D team operating in or with Europe, deploying live emotion-scoring on trainees is not a grey area. The combined message from the science and the law is the same: the job of reading the room belongs to the human facilitator, supported by behaviour you can legitimately observe, not by an algorithm guessing at inner states from pixels.
A facilitator’s playbook for the channel you actually have
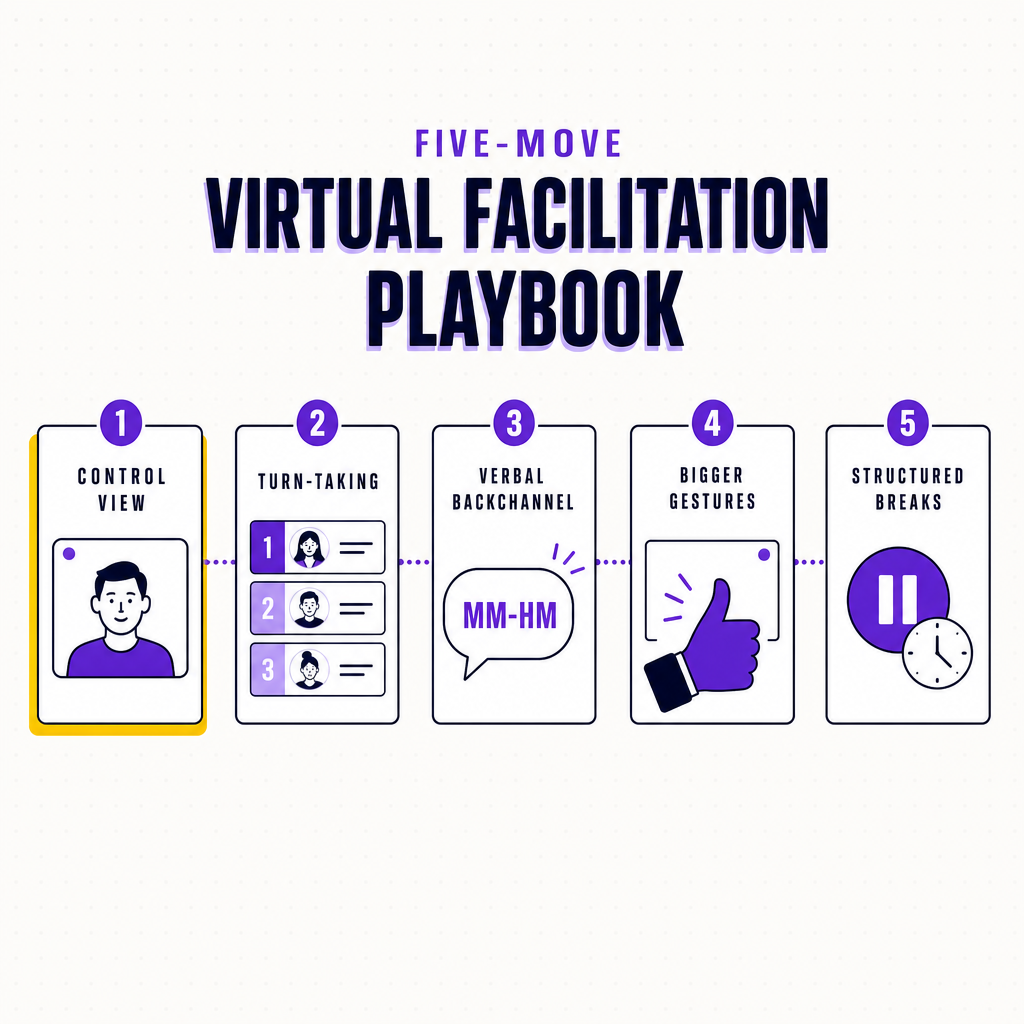
You cannot restore the missing cues, so design the session so people do not need them. Five moves do most of the work.
First, control the view. For focused instruction or close discussion, ask people into speaker view so the active speaker dominates rather than competing with nineteen other faces, and tell everyone to hide self-view to kill the all-day mirror (Stanford VHIL, 2021). Gallery view is for the social check-in, not the deep work.
Second, run turn-taking explicitly. Because latency has broken the natural hand-off, become a traffic controller. Name the person before you ask, “Priya, I’d like your read on this next,” which gives them time to unmute and signals to everyone else that they can stay quiet. Use raised hands, structured polls, or a named chat monitor to turn an ambiguous nonverbal queue into an orderly one.
Third, make the backchannel verbal. In a room, listeners nod and murmur to keep a speaker going, and online those signals vanish into tiny tiles. Set an explicit norm that short spoken affirmations, the “mm-hm,” “yes,” “got it,” are welcome, and the emotional temperature of the call changes. A speaker talking into apparent silence assumes the worst.
Fourth, ask for bigger gestures. When voice is not appropriate, such as in a large muted webinar, tell people to bring feedback into frame: an exaggerated thumbs-up to the lens, a clear nod, a reaction emoji. A subtle cue is invisible at tile size, so the cue has to grow to survive the medium.
Fifth, protect attention with structure. Shorter segments, real breaks with cameras off, and movement between blocks all counter the nonverbal-overload fatigue that otherwise degrades everyone’s signal quality by the second hour.
What this means for L&D and HR
The practical shift for anyone running virtual development is to stop measuring engagement by eye and start measuring it by behaviour. Self-report is weak, since people rate their own focus generously, and the on-screen read is exactly the channel this whole article has shown to be unreliable. The signals that do hold up online are behavioural and verbal: who actually speaks, for how long, who gets interrupted, who never gets the floor, how turn-taking distributes across a session.
That is the gap Team Building Bot is built to close. Rather than guessing engagement from a grid of faces or trusting a legally dubious emotion-scoring plugin, it observes the legitimate signals, airtime, turn-taking, and participation, and turns them into an Individual Communication Profile for each person. For a facilitator working blind through a webcam, that converts a wall of ambiguous tiles into something you can actually develop.
Frequently asked questions
Can you really read body language on a video call?
Only partially. Facial expression around the eyes and mouth, head movement, and vocal tone come through, but full-body posture, hand gestures below frame, physical distance, and genuine mutual eye contact are lost or distorted. The biggest blind spot is group-level reaction, the side glances and collective shifts that tell you how a room is responding together, which a grid of isolated tiles cannot show.
Is the 7-38-55 rule true for online meetings?
No. The figures come from two narrow 1967 experiments by Albert Mehrabian about resolving conflicting signals of feeling, not a general law that body language carries 93% of meaning. Misapplying it makes video calls seem almost communication-proof. In reality the channels that survive video best, words and vocal tone, carry far more of the message than the myth suggests.
Why are video meetings so tiring?
Stanford research attributes it to nonverbal overload rather than screen time alone (Bailenson, 2021). Four drivers stand out: an unnatural amount of close-up eye contact, the effort of sending and reading cues deliberately, constant self-view, and being locked motionless in frame. Hiding self-view, using speaker view, and taking camera-off breaks all reduce the load.
Should I require cameras to be on?
Make it a default invitation, not a rule. One field experiment found camera use raised fatigue, especially for women and newer employees (Shockley et al., 2021), while a classroom study found cameras supported engagement without extra fatigue. Context and group size shape the result, so normalise camera-off stretches and never treat a black tile as proof of disengagement.
Can AI tools read participants’ emotions from their faces?
Treat the claim with suspicion. The science is shaky, since facial expressions do not map cleanly onto universal inner emotions, and the legal ground has shifted: the EU AI Act has prohibited emotion-recognition systems in workplaces and education since February 2025. Reading the room remains a human job, supported by observable behaviour rather than algorithmic guesses about inner states.
The takeaway
Nonverbal communication survives the move online in a thinner, more fragile form. Faces and voices come through, gaze and posture get mangled, and the group-level signals you lean on most simply vanish. The worst response is to read harder, squinting at tiles for cues that are not there. The better one is to design around the gap: choose the right view, run turn-taking on purpose, move the backchannel into words and bigger gestures, and keep a firm scepticism about any tool that claims to read feelings off a webcam. Work with the channel you actually have, and the screen stops being something to fight.
More on Communication Styles
- arrow_forward Talking-Time Imbalance in Meetings: What Quiet Tells You
- arrow_forward 8 Warning Signs of Team Communication Breakdown in 2026
- arrow_forward Nonviolent Communication at Work: Conflict Scripts for 2026
- arrow_forward Assertive Communication: 30 Phrases That Work in 2026
- arrow_forward Interpersonal Communication at Work: 7 Habits of Trusted Colleagues
- menu_book Communication Styles at Work: The Complete 2026 Guide Pillar
See what's really happening in your online sessions, not what the grid suggests
Team Building Bot joins your virtual workshops and builds an Individual Communication Profile for each person: airtime, turn-taking, and how they engage, measured from behaviour rather than guessed from tiny video tiles. Free during beta.
No spam, no credit card. Unsubscribe any time.